摘要
- 一、常见性能优化要求
- 二、优化分析过程
- 三、性能分析工具箱
- 四、系统基础问题检查
万老师多年前的一篇内部分享,发布出来供有需要的同学参考。虽然今天的应用系统的复杂度跟过去会有所不同,性能观测工具、数据规模也不可以同日而语,但是正所谓一切历史都是当代史(“Ogni storia e la storia contemporanea”),厘清过去的问题是为了更好地理解现在和未来。为了保持原貌,编辑过程中基本遵循原文,之后也不再更新。
一、常见性能优化要求
在我经历的性能优化案例中,常见的问题都是这样开始的:
- a) 前台访问很慢,请帮忙分析优化
- b) 用户对性能很不满意,再不解决就要投诉
- c) 数据库负载很重,请帮忙分析一下
- d) XXX功能打开需要1分钟,请帮忙分析一下。
而等我访问这个功能的时候,可能几秒钟就返回;等你满怀困惑的找到问题提出人员,如果足够幸运的话,可能他告诉你要选择什么查询条件,问题能够重现;当然另一个可能是他也是转述用户的话。
在接到这些性能优化要求的时候,我都希望能够了解下面的信息以判断问题的类型,而通常情况下,我的工作都是在这些信息并不存在的情况下开始的
- a)系统性的问题? 比如CPU利用率,SWAP利用率或者IO过高导致的整体性能下降?
- b)功能性问题? 整体性能良好,个别功能时延很长
- c)新出现问题?什么时候开始的,之前系统有哪些变动?(升级或者管理的资源大量增加)
- d)不规律问题?有时候快,有时候慢,没有特定规律
- 还有性能快慢的衡量标准是什么?原来多少秒,现在多少秒,目标是多少秒?
只有上述问题得到了准确的回答,优化工作才能开始。
而获取上述答案的方法就是测量,有可靠的监控工具对用户的访问时延,系统的CPU,IO,SWAP进行准确的测量,当系统发生性能瓶颈时,系统当时的状态,数据库当时的状态进行及时的记录,依赖这些数据才能开始优化。
案例1,天津客户曾经有过投诉,系统经常性的出现整体性能下降,几乎无法访问的情况,而且发生的时间没有任何规律。
我部署了监控工具,3周后分析数据,发现访问性能下降之前用户都执行了某一个历史告警查询,而在此之后的数据库性能曲线也急剧下降。研发人员对此功能优化后,问题再也没有出现。
案例2,南京客户某主机经常崩溃,根据监控工具在崩溃前记录的进程列表看,是某个程序挂起导致的进程越积越多,资源耗尽而崩溃,对该程序改进后,故障再未发生。
之所以费这么多笔墨,就是希望能够让各位明白,没有定量的测量,性能优化工作完全是空中楼阁,无法进行。而通过工具的部署和监测,今后我们提出的性能问题可能就是这样:
- a) 系统整体负载正常,但/nms/res/devicelist_down.jsp目前经常出现35046毫秒的访问时延,请协助排查一下
- b) 系统SWAP利用率经常会超过50%,这时候系统响应很慢,杀掉GetCGFlux.pl后恢复正常,请分析一下
- c) 或者数据库服务器目前CPU利用率居高不下,已经持续了一段时间,请分析一下
如果性能优化工作以这样的方式开始的话,这项工作就会变得轻松有趣得多了。
二、优化分析过程
- 性能数据收集
这一步是性能优化的基础,如果问题系统之前没有部署监控工具的话,那么就要部署监控工具,收集一段时间的数据后才能开始分析;当然也有例外,幸运的话,性能问题正在发生并且如此显著,比如某个程序长时间无法挂起,或者某个进程把整台主机的CPU都吃掉,或者某个功能查询很慢,次次如此。当然这种问题也就很少需要到我这,你就可以直接找开发人员解决了。
很多情况,问题可能不是那么明显,也不是那么规律,可能也涉及到系统的多项功能,这个时候,我们就必须要借助于工具来进行数据的收集。 - 性能数据分析
如果没有数据收集,分析工作可能很神秘,完全依赖于专家的个人经验。以前听过一个故事,一个工厂的打印机总是莫名其妙的在某个时间出现故障,后来请了一个专家,搬了把椅子坐在打印机附近,几个星期后,叫工人把地板的某个角修好,之后这个问题再也没有出现。
但是有了之前收集的数据,观察CPU,IO,应用时延,网络性能等不同指标的曲线,观察问题出现的时间点,存在问题的功能,任何一个IT业者,都应该具备从这些数据中发现问题的能力。
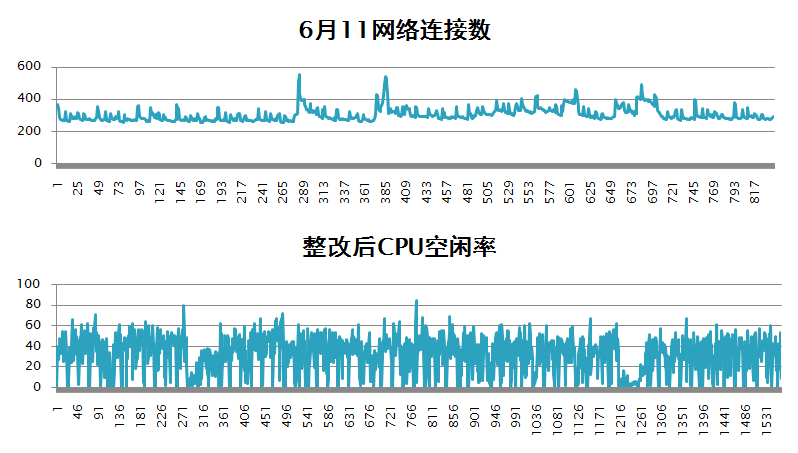
例如某台采集机SYSLOG处理经常出现会滞后的情况。而这台机器的网络丢包是这个样子的,那么问题是不是显而易见?

再比如有一个巡检功能,数据某个时段总是大量入库失败,那你看到数据库CPU和连接数在这个时段是这样的,数据库连接数增加,CPU空闲率为0,那么是不是问题也很明显了。

- 实施优化工作
这一步主要是针对之前发现的问题,采取措施。可能是系统维护人员调整采集负载,让负荷更均匀;或者调整主机或数据库参数;当然更多的可能是程序需要优化 - 评估优化效果
譬如上述第二个例子,采取优化措施后,无论是网络连接数还是数据库主机负载,都已经很平稳,而问题也不再出现。
如果没有达到,则不断重复上述四步,继续优化。
三、性能分析工具箱
这个工具箱是我常用的性能分析工具,曾协助我解决了很多的性能优化难题
- a) web访问时延监控工具AssayFilter
部署在主应用上
部署后可以在resin/logs/AssayFilter.log里面看到访问时间,访问的用户,访问的URL,时延毫秒,来源IP,据此我们就可以将用户的感知定量化,数据化从这两条数据里我们可以知道这个用户在访问这个功能时候遭遇过多次等待300多秒的情况,他又会有怎样的满意度呢?1
220150227094607 zengguojin /nms/res/devicelist_down.jsp 309356 219.159.77.116 ms
20150209113913 zengguojin /nms/res/devicelist_down.jsp 383042 219.159.77.116 ms
针对这个工具可能有人怀疑是否准确,是否统计时延过高是网络延迟导致。这里解释一下他的工作机制,
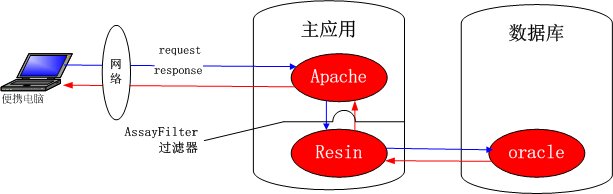
如下图:
AssayFilter作为一个拦截器,统计的是访问请求进入resin之后和应答离开resin之前的时长,访问时延=resin处理时长+主应用到数据库网络时延+oracle的SQL执行时长
主应用到数据库都在一个交换机上,所以主应用到数据库网络时延可以忽略不计。
所以,这个工具完全避免了网络延迟对访问时延统计的影响,让我们的精力完全聚焦在WEB应用自身的性能上.
b) 主机监控探针wd_probe
部署在主机上
这个监控探针除了能起到主机告警通知的作用,也是一个我依赖的性能分析工具,他能够记录各个时间点的CPU,SWAP,磁盘IO,网络性能,进程数量,网络连接数量的性能数据,当CPU超过预设阀值时会输出系统当时的进程快照用于事后的分析。
在探针主目录的data/perf下有性能数据,在data/tmp下有系统进程快照c) 数据库超长SQL收集工具
部署在主应用上,可以在cron里每分钟执行一次
这个程序会不断捕捉执行时间超过6秒的sql,记录进 /tmp/sql.csv文件中,运行结果如下:
从发起端看可分为两类,通常从APP发起的JDBC程序就是用户前台访问执行的SQL,而这种SQL执行时间超过6秒就是我们需要优化的SQL.

四、系统基础问题检查
- 主机基础故障问题
- 磁盘空间是否空闲为0?
- SWAP利用率是否超过40%?
- CPU利用率是否长时间超过85%?
- 网络是否持续丢包?
- 工作磁盘IO的利用率是否持续100%?
上述状况通常意味着系统有较严重问题,需要进一步从程序或者数据库上查找原因。
- resin的JVM检查
Web应用的前台程序jsp和class都是运行在resin的JVM里,JVM(Java虚拟机)类似于oracle数据库,jsp和class类似于SQL,都可以看作一个系统软件,那么仅仅是看java进程在不在,前台能不能访问是不够的。就像没有sqlplus,PLSQL我们就无法维护数据库,同样的JVM也有相应的维护工具,,都在JAVA_HOME/bin下
- a. 查看JVM的内存占用情况
1 | jstat -gcutil <pid> 3s 5 |
这条命令间隔3秒钟查看JVM的内存利用率,取样5次,
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 98.51 44.95 39.41 63.43 9 0.070 2 0.195 0.266
永久内存区利用率63.43%, Elden和old区分别是44.95%和39.41%
- b. 查看JVM的堆栈调用情况这条命令把当前JVM里所有的线程调用堆栈输出。在前台访问无响应的时候,排查故障根源时特别有用。
1
jstack <pid>

上述Thread-831被38f06e88的线程所阻塞,而根据调用堆栈,可以准确的定位到执行程序,进行排查。
- c. 查看错误日志是否有内存溢出错误
日志在resin/logs/error.log或者resin/log/jvm-default.log
如果有java.lang.OutOfMemoryError: PermGen space 说明JVM的永久内存区不足
-XX:MaxPermSize=256m 可根据永久内存区利用率调整到256M
java.lang.OutOfMemoryError说明JVM的堆内存不足
-Xmx2048m -Xms2048m 把堆内存调大到2048G
如果把Xmx加到2G,仍然会出现上述错误,那可能是有内存泄漏,需要开发人员排查
- 数据库检查
oracle排查比较复杂,我只能从两方面简单举几个例子。
- a) 系统参数层面优化
- sga是否充分利用了系统内存,sga可以配系统内存的一半. 而我遇到过主机64G内存,sga_target设置为5G
- db_cache_size最好在sga_target-3G,因为我们的程序很多没有使用绑定变量,如果不设置db_cache_size,则渐渐的SGA都有被share_pool占用的趋势,数据被缓存的越来越少,获取数据需要从磁盘读取,这样整体性能肯定会下降。
- shared_servers设置为0,让数据库运行在专有模式而不是共享服务器模式
虽然系统参数调整会在整体上带来一定的性能改善,但相比于糟糕的SQL或者程序设计以及失效的索引和过期的统计数据对性能起到的作用,还是很有限的。
- b) 应用优化层面
- 定位问题SQL
这个SQL能够列出数据库当前正在执行的所有SQL,基于两个判断标准我们能很快的找到问题SQL1
2
3select distinct s.sid,s.serial#,s.blocking_session,p.spid PID,to_char(s.logon_time,'YYYY-MM-DD HH24:MI:SS') logontime ,
substr(s.machine,1,15) smachine,substr(s.program,1,20) sprogram,q.sql_id,substr(q.sql_text,1,200) sql from v$sql q,v$session s,v$process p
where q.hash_value=s.sql_hash_value and q.address=s.sql_address and p.addr=s.paddr
- 第一种是某个进程执行的SQL占用的CPU非常高,CPU利用率从Top命令获得,进程ID即PID
- 第二种是某类进程执行的SQL非常多,单个CPU不高,但合并起来就非常高了。
针对SQL就可以找支撑人员进一步判断是否需要找开发人员优化。 - 是否存在session被其他session阻塞的情况
查看上一SQL结果的blocking_session字段,如果被阻塞的进程都被某一会话锁定,需要把该session杀掉
alter system kill session ‘sid,serail#’;
遇到过几次系统非常慢的情况,经查看都是开发或者维护用plsql把某表锁住,导致相关会话都被阻塞
- 是否存在session被其他session阻塞的情况
- 对该SQL所涉及的表进行表分析,更新其统计信息
- 定位问题SQL
性能优化非常精深,很多东西我也在学习,先把经常出现的一些问题解决经验总结出来,供大家分享。
扩展阅读:电子书《Linux Perf Master》

扩展阅读
- Linux 性能诊断:负载评估
- Linux 性能诊断:快速检查单
- 操作系统原理 | How Linux Works(一):启动
- 操作系统原理 | How Linux Works(二):空间管理
- 操作系统原理 | How Linux Works(三):内存管理
- 操作系统原理 | How Linux Works(四):网络管理
扩展阅读:动态追踪技术
- 动态追踪技术(一):DTrace 导论
- 动态追踪技术(二):strace+gdb 溯源 Nginx 内存溢出异常
- 动态追踪技术(三):Tracing Your Kernel Function!
- 动态追踪技术(四):基于 Linux bcc/BPF 实现 Go 程序动态追踪
- 动态追踪技术(五):Welcome DTrace for Linux
